
|
|
|
Главная -> Дистанционное зондирование 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 [122] 123 124 125 126 127 128 129 ходит их реализация. При выборе алгоритмов внимание должно» уделяться возможности извлечения информации с их помощью, эффективности их реализации и сложности для использования их аналитиком данных. При проектировании любой конкретной системы обработки необходимо согласование этих факторов. Очень мощный и сложный алгоритм для извлечения информации: может оказаться трудным для работы или использования аналитиком данных или для того и другого. Существует также зависимость между сложностью алгоритмов, данными и информацией, которую необходимо получить. Если данные, получаемые датчиком, очень простые и мало-спектральных каналов, оттенков серого и т. д., использование очень сложного алгоритма для анализа будет бесполезным. Аналогичным образом, если пользователю необходима только очень простая информация, опять вряд ли пригодится сложный метод: анализа. Продолжим рассмотрение вопроса о сложности алгоритма и перечислим некоторые характеристики, которыми могут обладать алгоритмы. Прежде всего, что касается алгоритмов-анализа, то к вопросу идентификации классов можно подходить как на абсолютной, так и на относительной основе. Вероятно, самым простым подходом к спектральной идентификации является постановка вопроса в абсолютном смысле. Суть этой точки зрения в том, что исследуемый класс представляет собой объект, а все остальное - фон. Например, на рис. VH.l? показана спектральная отражательная способность зеленой растительности. Мы можем поставить условие, что любой класс, имеющий такую спектральную характеристику, - это растительность, а все остальные-нет. Очень простой алгоритм для данного случая представляет собой указание дешифровщику локализовать на цветном аэрофотоснимке все классы зеленого цвета.. Заметим, что в этом случае не учитываются другие классы. Вспомним в этой связи один важный научный (и прагматический) принцип, который заключается в том, что относительные измерения выполнять легче, чем абсолютные, и что относительные решения принимать легче, чем абсолютные. Напри--мер, напряжение можно измерить точнее, если знать стандартное напряжение; решения лучше принимать, когда можно выбирать между альтернативами. В магазине красок гораздо легче выбрать краску того цвета, который подходит к Вашей гостиной, если у Вас есть с собой образец этого цвета, потому что-так Вам легче выбрать краску путем прямого сравнения. Этот лажный принцип используется в большинстве алгоритмов анализа, рассмотренных в гл. П1. Кроме того, следует помнить математическую модель для сигнала и шума, т. е. изменения характеристик, содержащие-необходимую информацию и не содержащие ее. Мы рассмотрим простую иерархию, которую можно использовать при разработке или выборе алгоритмов различной сложности. Детерминированный алгоритм или статистика первого порядка. Вернемся к вопросу о передаче информации через спектральное распределение энергии. Возможно, самая простая модель - такая, в которой каждый класс представлен одной детерминированной кривой отклика в зависимости от длины волны (см. рис. VII.17). Эту кривую можно было получить или детерминированно, или с использованием стлтистик 1-го порядка (усреднения большого числа спектров). Почвы  Дг:и1<а волны л Рис. VII. 17. Типичный спектральный отклик зеленой растительности 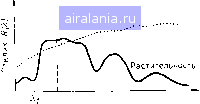 Длина волны Л Рис. VI 1.18. Типичный спектральный отклик зеленой растительности и почв Алгоритмы для моделей такой сложности могут быть соответствующими: например, при дифференциации между почвой и растительностью может подойти простое отношение диапазонов, использующее длины волн Xi и (рис. VII.18). Статистика 1-го порядка плюс шум. Хотя кривые (см. рис. VII.18) можно получить с помощью статистического усреднения, описанная выше модель может считаться детерминированной, потому что она прямо не объясняет статистические изменения данных. Более полная характеристика действительных спектральных данных должна включать статистические изменения средних спектральных кривых (рис. VII.19). В этом случае мы все же представляем себе сигнал в виде среднего спектрального отклика; однако известно, что есть компонента, которая не несет информации, т. е. случайный шум. Этот подход использовался на рис. 1.14, где видно, что, несмотря на статистическое различие, успешная классификация данных возможна при выполнении измерений в диапазоне 1,7 мкм, так как здесь нет перекрытия двух классов. Таким образом, алгоритмом дискретизации для этой ситуации может быть квантование по уровню, возможно, применяемое последовательно на нескольких каналах, если число классов больше двух и если неперекрывающиеся точки для различных пар классов находятся на различных длинах волн. Линейный дискриминантный анализ, показанный на рис. 1.10, также подходит для этой модели по своим основным принципам; хотя имеется статистический разброс данных классов, границы решения получаются только из средних значений, т. е. из усредненного спектрального отклика. Статистическая модель 2-го порядка. Еще более полная модель, передающая информацию через спектральные изменения, указывает на то, что хотя усредненный спектральный отклик как функция длины волны содержит большой объем информации, которую можно использовать для разделения классов, способ отклонения данных классов от среднего значения также может быть информативным. В этом случае мы. используем статистическую модель не только для изменений, не Длина волны X  Длина волны Л Рис. VI 1.19. Спектральный отклик зе- Рис. VI 1.20. Спектральный отклик зеленой растительности, показывающий леной растительности, показывающий случайные статистические изменения изменения второго порядка относительно средней характеристики содержащих информации (щума), но и для изменений, содержащих ее (сигнала). Теперь типичный отклик зеленой растительности будет таким, как показано на рис. VII.20, а не как представлено на рис. VII. 19, а тонкая структура, изображенная на рис. VII.20, важна потому, что она тоже содержит информацию. Эта модель предполагает использование алгоритмов, дифференциация с помощью которых основана не только на «среднем разделении» множеств данных в л-мерном пространстве, но также на Знании вида этих распределений. Именно это служит обоснованием схемы максимума правдоподобия, в которой используются многомерные статистики как 1-го, так и 2-го порядков. Границы решения в этом случае обычно являются сегментами кривых 2-го порядка. Так как характеристика информации, содержащейся в спектральных изменениях, становится более полной при выполнении только что описанной иерархии, можно ожидать, что характеристика классификатора улучшится. Для такого улучшения необходима точная локализация границ решения. При этом, возможно, потребуются большая точность оценки обучающих статистик, более представительные обучающие выборки, большее число обучающих выборок, данные лучшего качества и т. д. Точная оценка статистик 2-го порядка более сложна, чем статистик 1-го порядка. И, наконец, вспомним (разд. 1.3), что признаки используются как в многомерной форме, так и многократно одномерной форме. Рассмотрение рис. 1.15 дает многократный одномерный анализ данных, а рис. 1.17 - анализ этих же данных в мн@го-мерной форме. 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 [122] 123 124 125 126 127 128 129 0.0162 |