
|
|
|
Главная -> Дистанционное зондирование 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55] 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 Заметим, что выражение состоит из суммы двух членов. Первый член обусловлен только различиями между соответствующими ковариационными матрицами. Второй член - нормализованное расстояние между математическими ожиданиями. Dij никогда не равно О, пока и математические ожидания, и ковариационные матрицы двух классов не равны. Итак, мы имеем меру статистической разделимости двух классов, указатель вероятности ошибки при их разделении. Так как это дает нам меру относительной эффективности возможных наборов признаков при разделении классов, проблема от- 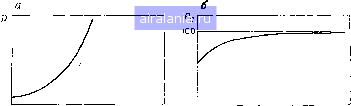 Нормализоеанное расстояние Нормализованное расстояние Рис. III. 18. Дивергенция и вероятность правильного распознавания как функции нормализованного расстояния: а - дивергенция D; б - вероятность правильного распознавания Р (в процентах) бора признаков в случае двух классов по существу нами решена, т. е. имея любую пару наборов признаков в случае двух классов, мы можем определить лучший набор, вычисляя для обоих дивергенцию и отбирая набор с наибольшей дивергенцией. Но как быть с т-классной задачей, когда т>2? Дивергенция- попарная мера расстояния, и обобщения на т классов не было сформулировано. Широко распространенная стратегия для многоклассной задачи - использовать среднюю дивергенцию, т. е. вычислять среднее по всем парам классов. Средняя попарная дивергенция Dcp определяется выражением /=1 1=1 (III.34) Это уравненное усреднение с априорными вероятностями классов в качестве весов. Отбор поднабора признаков, имеющего максимальную среднюю дивергенцию, конечно, разумная стратегия. В конце концов, максимизация средней попарной вероятности правильного распознавания (вероятность правильного распознавания просто равна единице минус вероятность ошибки) находится в соответствии со стратегией (байесовской) среднего минимального риска, которую мы приняли ранее. Однако дело в том, что применение этого метода имеет свои затруднения, поскольку по- .17-2 ведение дивергенции как функции нормализованного расстояния между классами значительно отличается от поведения вероят-ности правильного распознавания. Это иллюстрируется на рис. III.18. Общая форма графического представления дивергенции становится понятной при исследовании уравнения (III.33), представляющего выражение дивергенции пары нормально распределенных классов. Второй член суммы в правой части этого соотношения продолжает быстро возрастать по мере возрастания нормализованного расстояния между математическими ожиданиями. Легко узнать этот член как многомерное обобще- Предполагается, что р(ш,] = р(ш2) = р(шз) Класс 1 .-. Класс 2 ® Класс 3 © © ©
Puc. III.19. Пример, в котором значение Dave не оптимально (кружки обозначают относительное положение классов, но не обязательно их границы) ние нормализованного расстояния, введенного ранее [см. уравнение (III.27)]. Кроме того, вероятность правильного распознавания может возрастать только до 100%, и как только получено нормализованное расстояние, соответствующее наилучшему распознаванию, дальнейшее сколько-нибудь заметное улучшение качества распознавания невозможно. Влияние этого различия в поведении можно понять, рассмотрев простой пример на рис. III. 19. На нем схематически изображена задача отбора признаков, включающая два класса, которые относительно трудно точно разделить (возможно, кукуруза и соя), и третий класс, который легко отделяется от первых двух (скажем, обнаженная почва). Типичные значения дивергенции, соответствующие заданным величинам вероятности ошибки, приведены в работе -[6]. Набор признаков [хс, ха) предпочтительнее набора {Ха, хь), так как он дает лучшее разделение классов 1 и 2, почти не ухудшая выделение класса 3. Если же отбор признаков базируется на максимуме средней дивергенции, то отбирается набор признаков {ха, хь), дающий более низкое качество классификации. Это происходит потому, что поведение дивергенции как функции нормализованного рас- стояния пар классов заметно отличается от поведения вероятности ошибки как функции нормализованного расстояния. Теперь рассмотрим другую индикаторную функцию, котёрая в этой ситуации работает лучше. J-M расстояние Расстояние Джеффриса - Матусита (J-M), подобно дивергенции, является мерой статистической разделимости пар классов*. Формально оно определяется следующим образом: ij = {j [Kp (xI щ)- Vp (ХI СО;)] dx\ (ш.зз) Грубо говоря, f-M расстояние--это мера средней разности между функциями плотности для двух классов, что снова, как показывает интуиция, является разумным способом измерения разделимости классов. На данном этапе еще не очевидно, что J-M расстояние имеет какие-либо преимущества перед дивергенцией. Это, однако, становится очевидным, если сделать предположение, что классы имеют нормальные функции плотности. В этом случае выражение (П1.35) приводится к виду /г,. =[2(1-е-«)ГЧ (III. 36) 1 / Е;4-2,- \-1 I (2г + Гу)/2 I (III.37) 2 Ч(2П-2,-)/ Снова, как и в случае с дивергенцией, предположение о том, что классы нормально распределены, позволяет получить выражение, не содержащее интегралов и зависящее от математических ожиданий и ковариационных матриц классов; и снова мы узнаем член, который можно интерпретировать как многомерную форму нормализованного расстояния между математическими ожиданиями классов [сравните с уравнением (1И.27)]. Однако существует значительное различие благодаря члену с отрицательной экспонентой в уравнении (П1.36). Влияние этого члена выражается в том, что он дает экспоненциально уменьшающийся вес возрастающим разностям между функциями плотности классов. В результате расстояние J-M имеет «насыщающее» поведение, как показано на рис. П1.20, и оно намного ближе к поведению функции процента вероятности правильного распознавания, чем функция дивергенции. Теперь, если вычислить * Читатель, пренебрегающий математическими выкладками, возможно, пожелает пропустить материал до абзаца, следующего за уравнением [(III.37). 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55] 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 0.0116 |